
PHP users can use two client protocols to query MySQL 5.6 and later. Not only standard SQL access but also faster key-value access to InnoDB tables is possible using the Memcache protocol. The MySQL benchmark team reports crazy figures. Of course, on hardware that makes the average PHP meetup visitor roll his eyes and say “yeah, Oracle, *yawn*…”. I’ve repeated my plain PHP benchmarks on an i3 desktop. And, I’ve added Redis to the game.
Short recap
Some ten years ago, colleaguages teached me that some 50% of the time processing a simple SELECT column_a, column_b FROM table WHERE pk = <x> is spent on parsing and processing SQL. The actual data access only contributes to 50% of the overall run time. Thus, MySQL had always offered some lower storage layer API access through the HANDLER command. Fast forward ten years, you can query MySQL either through SQL, as ever since, or through the Memcache protocol. The latter will bypass the SQL layers, get you directly to the storage and thus be faster. The presentation has the details.
Given how popular read only query like SELECT column_a, column_b FROM table WHERE pk = <key> can be, it may be worth scanning your code for them and replacing them with ~2x faster Memcache accesses. PECL/mysqlnd_memcached tries to do this in an automated fashion. It will match your queries against a pattern and try to replace a key-value style MySQL SQL access to a MySQL Memcache access. Nice in theory but the pattern matching may take that much time that is it not worth it (see also here). Please, run your own tests.
| PHP | |
| ext/mysqli, PDO_MYSQL, … | PECL/memcached |
| | | |
SELECT column_a, column_b FROM table WHERE pk = <key> |
GET <key> |
| | | |
| InnoDB SQL table | |
If automatic mapping from SQL to Memcache protocol may be too slow, manually replacing some calls is certainly not.
MySQL 5.6 Memcache vs. MySQL 5.7 Memcache vs. Memcache vs. SQL
To see whether MySQL 5.7 Memcache access is faster than MySQL 5.6 Memcache access, I’ve rewritten my PHP benchmark script. The basic procedures are exactly as before. I’m using PHP 5.7.0-dev with PECL/memcached 2.2.0b1 (libmemcached 1.0.16), mysqli, phpiredis. MySQL 5.7.3-m13, MySQL 5.6.15, Memcache 1.4.15, Redis 2.8.2 and PHP have been compiled from source using all defaults. The computer being tortured is a budget i3-2120T CPU @ 2.60GHz, 8GB RAM, Linux RAID-0, ext4, OpenSuse 12.1 desktop PC.
Here are the results for random key/value accesses with a key length of 100 bytes, values of 400 bytes lenght and 25.000 values in total. All reads have been repeated a couple of times to ensure that runtimes are not too short. PHP, Memcache and MySQL all run on one box. PHP uses heavyweight fork() to span workers for concurrent access to the data stores. The graph shows the average number of operations per second as observed by a single PHP worker. If running on the box 1x MySQL 5.7 w. Memcache and…
- 1x PHP process, PHP script does 21556 ops
- 2x PHP processes, each PHP does on average 21538 ops
- 3x PHP processes, each PHP does on average 17816 ops
- …
As expected the small CPU cannot handle more than 4-8 concurrent PHP processes sending queries as fast as they can: beyond that point each PHP processes will observer a significantly lower number of operations per second. Please, note the graph does not show the data stores’ view which would be total number of the answers to any client per second.
If you prefer a different graph: the benchmark script is at the end of the blog posting :-).
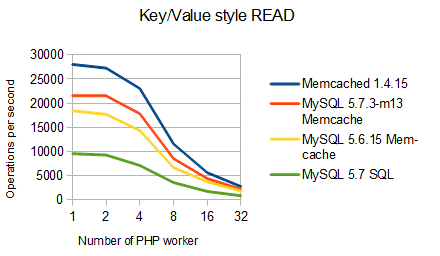
The results confirm prior findings:
- MySQL 5.7 Memcache InnoDB access to SQL table reaches ~75% of the performance of a cache
- MySQL 5.7 Memcache access is ~2.2x to ~2.5x faster than SQL
- MySQL 5.7 seems ~ 20% faster than MySQL 5.6
It is cool to see a SQL system come close to the performance of a cache but the rest of the story is boring: new version, seems a bit faster on small boxes, could be way faster on Facebook-style boxes.
MySQL vs. Memcache vs. Redis
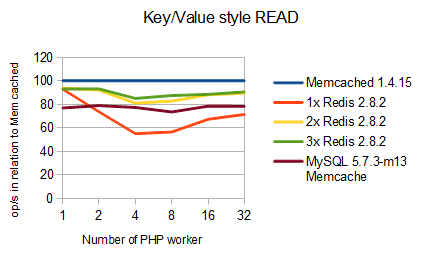
Comparing with Redis is hard but fun. The REmote DIctionary Server is more than a cache storing BLOBs. It handles complex data structures, such as lists or sorted maps. Redis offers neat publish-subscribe messages queues and much more. Still, it can be used as a cache. So can MySQL. Any quick benchmark is doomed to ignore this. So do I.
I am also ignoring the asynchronous API of Redis, which may bear significant tuning potential. Our MySQL Cluster folks love the asynchronous API for their benchmarks…
Redis is single threaded. One Redis instance cannot utilize more than one CPU thread. Redis likes fast CPUs but does not know what to do with a multi-core monster. This effect does not kick in on crazy 48-way boxes only but already my i3 desktop. MySQL uses all cores and CPU thread it gets, Redis is limited to a single CPU thread. Thus, for a fair comparison, I have to start multiple Redis instances. It is then the application developers task to pick the appropriate Redis instance.
| Core 1 | |
| CPU Thread 1 – Redis | CPU Thread 2 |
| Core 2 | |
| CPU Thread 3 | CPU Thread 4 |
An i3 has two cores and counting in hyper-threading 4 CPU cores. Therefore, I’ve compared MySQL and Memcache with 1, 2 and 3 Redis instances running. PHP workers are assigned in a round robin fashion to the Redis instances based on the workers process id. All instances are loaded with the same data set for the read-only test.
| Core 1 | |
| CPU Thread 1 – Redis 1 | CPU Thread 2 – Redis 2 |
| Core 2 | |
| CPU Thread 3 – Redis 3 | CPU Thread 4 |
Here’s the result: MySQL 5.7 InnoDB Memcache beats a single Redis 2.8.2 on read performance. If and only if, you use Redis inapproriately. If you bite the bullet and, for example, you partition your data across many Redis instances, then Redis is faster. However, at least on my desktop the difference is not in the order of magnitudes which is quite amazing for a SQL database.
Closing ramblings
In the past decade MySQL has constantly managed to utilize latest generation of commodity hardware CPUs efficiently. Whether it was 4-core, 8-core or now 48-core (or more CPU’s), we’ve been there. In the past three years, since Handlersocket appeared, there is a hunt for higher and higher benchmark results in terms of queries per second. I understand that MySQL flagship customers demand such performance.
However, when speaking at a local PHP meetup a 48-core benchmark is worth little more than a good laugh. First, the machines are out of reach. The majority of the audience will use 8-core/32GB max. Some have less than three such machines in total. Second, as exciting it is to learn MySQL can do 1,000,000 queries/s, the PHP meetup visitor sometimes wants to hear about how his job as a developer becomes easier when using this or that data store.
Again, MySQL read performance is close to cache performance. Wow! Maybe writes could be even faster – please run your own tests. My benchmark script is below. It can do writes as well.
But, what about usability and features that make application development easier? Did we forget about that?
Happy hacking!

Pingback: Ulf Wendel: PHP Memcache access to MySQL 5.7, faster? Redis? | facebooklikes
Pingback: Ulf Wendel: PHP Memcache access to MySQL 5.7, faster? Redis? | htaccess