
Inspired by Antony, Andrey has implemented a memory optimization for the PHP mysqlnd library. Depending on your usage pattern and the actual query, memory used for result sets is less and free’d earlier to be reused by the PHP engine. In other cases, the optimization will consume about the same or even more memory. The additional choice is currently available with mysqli only.
From the network line into your script
Many wheels start spinning when mysqli_query() is called. All the PHP MySQL APIs/extensions (mysqli, PDO_MySQL, mysql) use a client library that handles the networking details and provides a C API to the C extensions. Any recent PHP will default to use the mysqlnd library. The library speaks the MySQL Client Server protocol and handles the communication with the MySQL server. The actions behind a users mysqli_query() are sketched below.
The memory story begins in the C world when mysqlnd fetches query results from MySQL. It ends with passing those results to the PHP.
| PHP script | mysqli extension/API | mysqlnd library | MySQL |
|---|---|---|---|
| *.php | *.c | ||
mysqli_query() |
|||
PHP_FUNCTION(mysqli_query) |
|||
MYSQLND_METHOD(query) |
|||
simple_command(COM_QUERY) |
|||
COM_QUERY |
|||
store_result() |
|||
return result set |
|||
The new memory optimization is for buffered result sets as you get them from mysqli_query() or a sequence of mysqli_real_query(), mysqli_store_result(). With a buffered result set, a client fetches all query results into a local buffer as soon as they become available from MySQL. In most cases, this is the desired behaviour. The network line with MySQL becomes ready for a new command quickly. And, the hard to scale servers is offloaded from the duty to keep all results in memory until a potentially slow client has fetched and released them.
The result buffering happens first at the C level inside the mysqlnd library. The buffer holds zvals. A zval is internal presentation structure for a plain PHP variable. Hence, think of the mysqlnd result buffer as a list of anonymous PHP variables.
| PHP script | mysqli extension/API | mysqlnd library | MySQL |
|---|---|---|---|
| *.php | *.c | ||
| … | |||
store_result() |
|||
| Buffer with zvals (MYSQLND_PACKET_ROW), think: PHP variables |
|||
The default: reference and copy-on-write
When results are to be fetched from the mysqlnd internal buffers to a PHP script, the default behaviour of mysqlnd is to reference the internal buffer from the PHP script. When code like $rows = mysqli_fetch_all($res) is executed, first $rows gets created. Then, mysqlnd makes $rows reference the mysqlnd internal result buffers. MySQL results are not copied initially. Result set data is kept only once in memory.
| PHP script | mysqli extension/API | mysqlnd library | MySQL |
|---|---|---|---|
| *.php | *.c | ||
| … | |||
store_result() |
|||
| Buffer with zvals (MYSQLND_PACKET_ROW), think: PHP variables |
|||
$rows = mysqli_fetch_all($res)
|
|||
rows[n] &= result_buffer_zval[n] |
|||
The reference approach works fine if you have code that follows the general pattern: query(), fetch() followed by implicit or explicit unset(), free().
A call to query() fills the internal buffer. Then, all rows are fetched into PHP variables. You may fetch all of them at once or read them row by row into the same array using a pattern such as while ($row = $res->fetch_assoc()) { ... }. As long as you do not modify $row and free $row explicitly (may happen implicitly by overwriting them in a loop), no data will be copied. Then, as the last step you call free() to dispose the buffered result set.
$res = mysqli_query(...); /* create internal buffer */
$rows = $res->fetch_all(MYSQLI_ASSOC); /* rows &= internal buffer */
unset($rows); /* remove references */
$res->free(); /* free internal buffer */
The memory saving by using references is gone, if mysqlnd is forced to perform a copy-on-write. If you free the result set prior to freeing $rows, then mysqlnd is forced to copy the data into $rows before it can free the internal buffer. Otherwise, $rows points to nowhere.
$res = mysqli_query(...) /* buffered results */ $rows = $res->fetch_all(MYSQLI_ASSOC) /* rows &= internal buffer */ $res->free(); /* free internal buffer: copy to rows */ unset($rows) /* free copied results */
The copy_on_write_saved and copy_on_write_performed statistics tell you what your code does.
When I say that memory is free’d I mean that it is given back to the PHP engine. The PHP engine may or may not release it to the system immediately. If you are just after monitoring how mysqlnd behaves, check the statistics, or go for huge result sets to ensure the garbage collection kicks in to make effects visible.
The price of copy-on-write: management overhead
Copy-on-write does not come for free: mysqlnd must track variables that reference the internal buffer. This adds some memory overhead (zval**). And, the internal tracking list must not point to nowhere . As long as the tracking list exists, the referenced user variable – here: the elements of $rows – must not be released. There is kind of a circular reference. The resulting overhead is two-folded: there is an additional tracking list and the references from elements of $rows might occupy memory until free() is called. But, you save holding query results twice in memory. So the question is what takes more memory, and when?
| PHP script | mysqli extension/API | mysqlnd library | MySQL |
|---|---|---|---|
| *.php | *.c | ||
| … | |||
store_result() |
|||
| Buffer with zvals (MYSQLND_PACKET_ROW) | |||
$rows = mysqli_fetch_all($res)
|
|||
assign rows[n] &= result_buffer_zval[n] |
|||
remember rows[n] belongs to result_buffer_zval[n] |
|||
increase rows[n] reference counter |
|||
The answer depends on your code and the size of the result sets. If you fetch some few thousand rows at most on your one PHP server, it does not matter much how mysqlnd manages the result sets. The implementation detail impact is not worth optimizing: the impact is small and it takes time consuming fine tuning to find the optimum. But for Antony it mattered: likely, he handles PHP at scale…
New: classical copy as an alternative
At times it is more efficient to bite the bullet and to copy data from the internal buffer into user variables. It may sound counter intuitive but this may help to ‘save’ memory. ‘Save’ must not only be measured in absolute terms at a given point in time. This is what the figures below will show as it is easy to grasp. When done with reading ask yourself what it means to release memory early during the execution of one or many scripts, think of memory usage over time.
| PHP script | mysqli extension/API | mysqlnd library | MySQL |
|---|---|---|---|
| *.php | *.c | ||
| … | |||
store_result() |
|||
| Buffer with zvals (MYSQLND_PACKET_ROW) | |||
$rows = mysqli_fetch_all($res)
|
|||
assign/copy rows[n] = result_buffer_zval[n] |
|||
Every optimization is a trade: the COPY don’t do
The new always copy policy can be enabled using mysqli_store_result(MYSQLI_STORE_RESULT_COPY_DATA). Let’s consider a case that seems to prove one cannot ‘save’ memory by duplicating data. The code runs a single SELECT that returns a result set of 200.000 rows. Anything big enough to make the basic principles discussed visible through memory_get_usage(true) works. Then, all rows are fetched into using fetch_all() and the result set is released.
$link = new mysqli("127.0.0.1", "root", "", "test", 3307);
$link->real_query("SELECT * FROM test LIMIT 200000");
$res = $link->store_result(MYSQLI_STORE_RESULT_COPY_DATA);
$rows = $res->fetch_all(MYSQLI_ASSOC);
$res->free();
The diagram shows the memory usage reported by memory_get_usage(true) immediately after the function calls. The default behaviour is to make $rows reference (red, NO COPY) the internal buffer. The blue line shows the effect when $rows gets populated with copies. The initial memory usage of the reference approach is lower until free() is called. Now copy-on-write must be done and either approach uses the same amount of memory.
BTW, don’t get nervous about the huge figures. This is what happens if you create large PHP arrays…

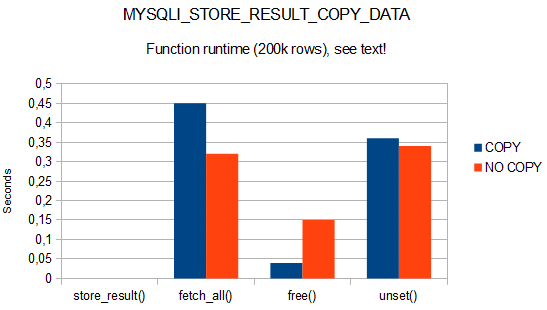
Function runtimes measured with microtime(true) are as expected. The reference approach is a tad faster when $rows is to be populated but has some hidden costs at free() when the internal buffer reference lists are to be checked.
For this very script, with this very result set, version of MySQL and PHP and notebook there was no significant difference in total runtime. Only a minor tendency of MYSQLI_STORE_RESULT_COPY_DATA being ever so slighty slower became visible. This meets expectations due to the additional memory copies and allocations.
Counter example done, time to show the potential win
Copying result sets is no significant win when you have many rows and use fetch_all(), when you have few rows at all (point SELECT, paging with LIMIT, few hundret rows overall). Or, if you have few large rows with, for example, BLOB columns. In those cases, there is no need to bother about the flavour of the mysqlnd result set handling.
The code to try the copy optimization with should:
- fetch many, rather small rows
- and, should not use
fetch_all() - or… is sloppy with
free()(bad style, use mysqlnd statistics to identify such scripts)
Replace the fetch_all() with while ($row = $res->fetch_assoc()) in the 200k rows result set example and you immediately see the potential of Antony’s proposal:
$link->real_query("SELECT * FROM test LIMIT 200000");
$res = $link->store_result(MYSQLI_STORE_RESULT_COPY_DATA);
while ($row = $res->fetch_all(MYSQLI_ASSOC)) {
;
}
$res->free();
Peak memory reported for this code is 1808 KB (~2MB) versus 50368 KB (~49 MB) for the referencing logic! But the runtime is about 10% slower. As with all those benchmarks: run your own! I am showing trivial microbenchmark observations only to highlight the principles behind. I did not even bother to align the negative values reported by memory_get_usage()…

The lower peak memory usage is because the memory used for $row can now be released as the result set is being iterated.
| Pseudo code to illustrate copy logic during fetch loop | ||
|---|---|---|
| PHP call | PHP internals | memory objects |
| store_result() | Create internal_row_buffer[] |
|
| $row = fetch_assoc() | create $row, copy internal_row_buffer[0] into $row |
|
| $row = fetch_assoc() | free $row, copy internal_row_buffer[1] into $row |
|
Obviously, with the copy technique, there is no reference from the mysqlnd library to $row because mysqlnd does not have to bother about copy-on-write and the like. $row contains a copy of the actual data from MySQL and no longer points to the mysqlnd internal result buffer. The table below tries to illustrate the situation when data copies are avoided and references are used:
| Pseudo code to illustrate reference logic during fetch loop | ||
|---|---|---|
| PHP call | PHP internals | memory objects |
| store_result() | Create internal_row_buffer[], internal_reference_list[] |
|
| $row = fetch_assoc() | create $row, $row = &internal_row_buffer[0]; internal_reference_list[0] = $row; |
|
| $row = fetch_assoc() | $row = &internal_row_buffer[1]; internal_reference_list[1] = $row; |
|
| n-th $row = fetch_assoc() | … |
|
| unset($row); free_result($res) | free(internal_row_buffer); free(internal_reference_list) | empty |
Don’t get too excited. The copy approach is not an ultimate solution. There are many factors to consider: actual code, actual statements and the size of their result sets, your servers demands. And, don’t even try to count bytes: some hundret or even thousand bytes here and there may not matter much. Write proper code (explicitly calling free()) and check your servers reaction.
The key takeaway: try MYSQLI_STORE_RESULT_COPY_DATA
The key takeaway is: try MYSQLI_STORE_RESULT_COPY_DATA if you have result sets with many rows. The copy approach will release memory faster to PHP for reuse and thus peak memory usage may be significantly lower. Again, be warned that I have choosen my examples carefully to show a hefty difference when doing point in time memory measurements. There may be a broad grey area for which you need to consider memory usage over time and possibly over many scripts to decide whether copy or reference fits your bill.
Ready for use?
Yes, the code is ready for use! The patch was running in production for a while and I failed to break it with tests too.
A new PHP configuration setting mysqlnd.fetch_data_copy has been introduced. Setting mysqlnd.fetch_data_copy=1 makes mysqlnd use and enforce the copy approach for all buffered result sets.
Not for PDO yet
The copy approach is not compatible with PDO_MySQL, though. PDO_MySQL relies on the zval reference logic and must be updated first.
Credits to A + A = A+ ?!
The manual has got a few words on it too but not substantially more than is above. The changes should bubble through build, staging and mirror servers within a few days.
Happy hacking!

Pingback: Link del giorno 11/04/2014 | Catnic Blog