
When you design a distributed database you are faced with a variety of choices each having its well known pro’s and con’s. MySQL Fabric made an intial decision for one design. Let me try to put in context of NoSQL approaches to degree I understand the matter. Understanding the data model is key to understanding Fabric. There are limits: by design.
Fabric?
MySQL Fabric is an administration tool to build large “farms” of MySQL servers. In its most basic form, a farm is a collection of MySQL Replication clusters. In its most advanced form, a farm is a collection of MySQL Replication clusters with sharding on top.
There are plenty of presentations on slideshare and blog postings on PlanetMySQL to get you started. If you don’t know Fabric yet, please, consult them first. I’ll not present a practical view on Fabric but theoretical ramblings on the data model.
Recap: desire vs. reality
Scaling data stores beyond a single machine is a challenge. He hope is that the more servers work together in a distributed database, the higher the throughput. Distributed databases shall be always available, be scalable and offer distribution transparency.
From an application developers point of view distribution transparency is probably the most important one. Developers would love to use synchronous (eager) clusters. All servers shall show all the updates immediately. Developers would love to be able to send all queries to any of the servers around without bothering about read or write (update anywhere). Developers would love see a sytem where every server stores all data to answer any question (full replication).
Sorry, Fabric will disappoint. Why? … be warned, I take an even more theoretical route to argue than usual. And, I usually already get to hear I need to take a more practical view…
Replication has hard scalability limits. If all servers shall be able to answer all read questions, then all your data must be on every server of the cluster. If – sooner (eager/synchronous) or later (lazy/asynchronous) – all updates shall appear on all servers, then the updates must be applied to all servers. Classically, such clusters follow a ROWA approach: Read One, Write All. A ROWA system can run all reads locally one a single server without interaction with other systems. Whereas all write operations require coordination with all the other systems.
(Tilt?! Work through slides 25 and following. NoSQL systems sometimes offer tuning options but no ultimate solution. Not tilt?! Enjoy the precise differentiation between replica and node that Mats applied to the Fabric manual versus my writing.)
Simplified ROWA scalability approximation
Every server (replica or node, not making a differentiation here for simplicitly) in a ROWA cluster has to handle:
- L = its own local work (reads and writes) – productive work
- R = remote work (because all writes affect all servers) – unproductive work
The processing capacity of every server i in a ROWA cluster is Ci = Li + Wi. The server has to handle productive local work and unproductive remote work. First, simple lesson: a server i of a ROWA cluster will always be “slower” than a standalone server. The standalone server has no extra unproductive work to do.
We can put the server in a ROWA cluster in relation to a standalone server to get an estimation about the scaleout capabilities of the system: scaleout = ∑i=1nLi / C. Looks worse than it is. It only sums up the values for all servers in the cluster.
Next, we need an estimate for the remote work. That’s the write load that affects all the servers in the cluster. There are two ways of to apply the writes on remote servers:
- symetric update processing = all local writes are replayed at the remote servers
- asymmetric update processing = remote servers apply writesets (the actual changes) instead of the operations
Reminds you remotely of MySQL Replication formats: statement-based vs. row-based vs. mixed? Yes, that’s roughly the real life counterpart to the theortical model.
For symetric update processing, we can assume: Ri = w * (n – 1) * Li. Skipping a few steps and cheating with using a nice book, we end up with: scaleout = n / (1 + w * (n – 1)). For asynmetric processing we shall make a guess how efficient it is compared to symetric. If, for example, we assume applying writesets takes 1/4 or fully executing write operations, then wo = 0.25. One ends up with scaleout = n / (1 + w * wo * (n -1)).
(You did not believe I would understand this, did you? That’s Mats’ or MySQL Cluster folks skill level not mine! I need books to cheat.)
The hard earned, easy to grasp graphics
Armed with those formulas you can make a rough estimation of replication scaleout limits. Below is the plot for scaleout = n / (1 + w * (n – 1)). That’s ROWA, symetric update, write ratio from w=0.0 (0%) to w=1.0 (100%) and 1 to 16 servers. Read loads scale perfectly. With only 10% write load, you reach a scaleout factor of 4 with some six machines. It requires six machines to handle the load four standalone servers managed to handle. If you double the number of servers to 12, you are not even reaching the processing capability of six standalone servers.
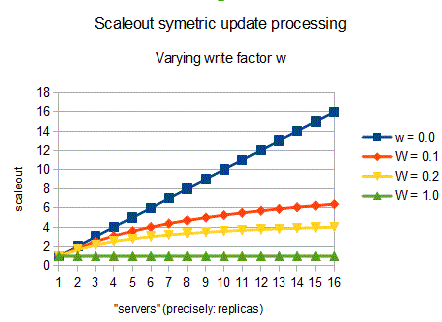
I was too lazy to plot a graph for asymmetric update processing. However, it only shifts the picture a bit as you already can tell from the formula: scaleout = n / (1 + w * wo * (n -1)).
Before you ask: the above hints the theoretical scaleout potential of Galera/Percona Cluster – strong on distribution transparency, not so strong on scaleout.
Partial replication
Sorry, dear developers, nobody can give you the best possible distribution transparency together with the best possible scaleout. However, if users are willing to trade in a bit of the distribution transparency, scaleout capabilities become dramatically better!
The solution is to allow that not every server must have all the data. If a data item has copies at only r<=n servers (nodes), then the remote work does not comes from n-1 but only r-1 servers. The formula for partial replication and asymmetric update processing becomes: scaleout = n / (1 + w * wo * (r – 1)). Here’s the resulting graph for w = 0.2 (20% writes) and wo = 0.25 (asymmetric update four times more efficient than symmetric update). Stunning, ain’t it?
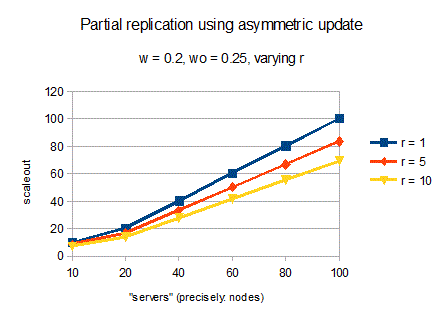
Welcome to MySQL Fabric (limit: thousands of nodes) and sharding! Or, MySQL Cluster at a smaller scale (limit: tens of nodes but millions of transactions per second). MySQL Cluster is also using sharding. Horizontal partitioning (sharding) is one approach for partial replication. There are two major reasons for using sharding:
- single server cannot handle the amount of data
- single server cannot handle the write load
The price you, as a user, have to pay is on distribution transparency:
- you may have to choose a specific server using some rules
- some questions cannot be answered by a single server, you have to collect answers from many
The first one is cheap with MySQL Fabric: provide a shard key, compute which server to use, send your queries there. The second one is expensive. Very expensive, depending on your needs. Again, depending on your needs, this (2) is where NoSQL systems may beat Fabric big times. Stay tuned, I am not talking MapReduce here! Data model, queries and scaleout capability go hand in hand.
Quick recap on MySQL Fabric
As said, if you are new to MySQL Fabric, please read some introduction first. For example, MySQL 5.7 Fabric: Introduction to High Availability and Sharding. Below is a quick recap on the data model and the replication model employed by Fabric. As you can see, it is optimized to scale writes on sharded tables. Reads are only fast if they cover no more than one partition of a sharded table plus any number of global tables.
| MySQL Fabric data model | |||||
|---|---|---|---|---|---|
| Global Group | |||||
| All unsharded tables | g1…gn | ||||
| Shard Group for tpartition:1 | Shard Group for tpartition:n | ||||
| g1…gn | g1…gn | ||||
| tpartition:1 | tpartition:n | ||||
Replication based on primary copy for High Availability and read scale-out. Write scale-out is added by using horizontal partitioning. Clients query a distributed (future) middleware (Fabric) for catalog information. Clients pick servers depending on user/application provided shard keys and catalog information.
| MySQL Fabric replication details | |||||
|---|---|---|---|---|---|
| Global Group | |||||
| Primary Copy cluster | |||||
| Shard Group 1 | Shard Group n | ||||
| Primary Copy cluster | Primary Copy cluster | ||||
| Copy of global group | Copy of global group | ||||
| Primary of tpartition:1 | Primary of tpartition:n | ||||
Fabrics weak spot
In the worst case a Fabric user asks a question that covers all partitions of a sharded table. No single MySQL server in the farm can answer the question, no single server stores all the data. Worse, there is no single server in the farm that can understand your intention behind question and warn you that it can’t give you a meaningful reply! There’s no way for a server to know whether you intended to query all shards or the partition on one shard.
SELECT shard_key, other_column FROM t1 ORDER BY other_column |
||||
|---|---|---|---|---|
| | | | | | | ||
| Shard 1 | Shard 2 | Shard 3 | ||
| t1(0..1000) | t1(1001..2000) | t1(2001..3000) | ||
Database theory knows about the challenge and there are several solutions to problem. The below list is roughly ordered by distribution transparency. Highest distribution transparency (“user-friendliness”) first, lowest last:
- hybrid model: full replication servers in addition to partial replication servers (here: shards)
- improved federated storage engine (similar to Oracle database links) such 3rd party Spider
- MySQL 5.7 multi-source replication
- middleware based query engine/aggregator
- driver based query engine/aggregator
From a users perspective it would be best if there was a server that could answer all questions because it would have all data from all partial replication servers in one logical data model. It would be then the servers task to translate queries that spawn multiple partial replication servers (here: shards) in appropriate access pattern. This is more or less what MySQL Cluster does behind the scenes (docs, presentation). When using MySQL Cluster, sharding is 100% transparent on the SQL level. The big advantages of transparency is the biggest drawback. Users and sales forget all to easy that a lot of networking is going on that will slow things down.
| Full replication query server using remote database links (no local data materialization) |
||
| Logical t0..3000 | ||
CREATE TABLE t1all(...) ENGINE=SHARDING PARTITION_CONNECT=user:password@Shard1 PARTITION_CONNECT=user:password@Shard2 PARTITION_CONNECT=user:password@Shard3(Using UNION something similar might be possible with ENGINE=FEDERATED.)
|
||
| | | | | | |
| Shard1 | Shard2 | Shard3 |
| t1(0..1000) | t1(1001..2000) | t1(2001..3000) |
If done properly, this is a very nice approach. The server takes care of distributed transactions (MySQL Cluster, Spider: pessimistic, 2PC), the server takes care of all SQL and tries to use “push down conditions” to minimize the amount of data sent around. There are no major negatives but, maybe, MySQL lacks it (= time to develop) and product differentiation with MySQL Cluster.
Please note, this is not the best approach if the majority of your queries is accessing one partition only. For example, Spider, adds latency to queries that access individual partitions only. But that’s not the question here. Anyway, if I was a power-user considering the use of MySQL Fabric, I’d evaluate this option very thoroughly. Maybe, I would even extend Fabric to setup and manage such full replication servers and teach my clients to use them.
| Fictional hybrid replication approach on top of Fabric | ||
|---|---|---|
| Global Group | Full Replication Server | |
| Queries on unsharded tables | Queries spawning multiple partitions | |
| Primary | One or more servers | |
| Copy1 | Copyn | |
| Queries on global tables and one partition per shard | ||
| Shard1 | Shardn | |
| Primary | … | |
| Copy1 | Copyn | |
Another hybrid solution that works out-of-the box would be using MySQL 5.7 multi-source replication to merge shards on server. Although this is easy to setup it has one obvious killer-disadvantage: data is physically materialized on one server.
| Full replication query server (using local data materialization) |
||
| t1(0..1000) | t1(1001..2000) | t1(2001..3000) |
| Shard1 | Shard2 | Shard3 |
| | | | | | |
| Multi-Source Replication | ||
| Full replication query server | ||
| t0..3000 | ||
As said above, sharding is applied for two reasons: either size of an entity or write scalability limits. If sharding is applied to reduce the volumne of data a server can handle, how could one build one server that handles all the data… If sharding is applied mostly because of write scalability reasons, this is a low hanging fruit to solve the distributed query problem. Ignoring all questions about the lazy (asynchronous) nature of MySQL Replication and stale data, this is a very sexy approach: no expensive distributed transactions! It even fits the marketing bill. Use slave for OLAP is no new story.
SELECT shard_key, other_column FROM t1 ORDER BY other_column |
||||
|---|---|---|---|---|
| Middleware or client library handling cross-partition queries (local data materialization, not SQL feature complete) |
||||
| | | | | | | ||
| Shard 1 | Shard 2 | Shard 3 | ||
| t1(0..1000) | t1(1001..2000) | t1(2001..3000) | ||
Finally, one could try to use a middleware or client library for gathering data from multiple partitions. This seems to be the road that Fabric plans to use. This approach will scale by client/middleware but there is no code one could reuse, for example, to process the ORDER BY clause in the example. Furthermore, the problem of materializing will remain. Problems have to solved for each and every driver again (read: different programming languages, no way to use one library for all). Most likely, none of the drivers will ever become as intelligent as a servers’ optimizer. I have no clue what the strategic goal is here.
Distributed transaction control is likely to be pessimistic including distributed locks and potential for deadlocks (a 2PC/XA classic, see slide 30 and following for details).
Are NoSQL data models any better?
There are many reasons why NoSQL solutions became popular. Considering the aspect of cloud and web-scale only, their biggest achievement might be reminding us of, or even inventing, data models that scale virtually indefinitely. Of course, partial replication is used… divide and conquer rules.
The first wave of major NoSQL systems was designed around key-value data models and sharding. The leading systems are BigTable, Dynamo and PNUTS with many open source projects that followed their ideas: HBase, Cassandra, Voldemort, Riak, [Big]CouchDB, MongoDB and many more.
| Key-value table variations | ||
|---|---|---|
| Name | Value structure | Notes |
| Blob data model | BLOB | Value is uninterpreted binary |
| Relational data model | Fixed set of columns. | MySQL/SQL-92: Flat (scalar) values only (related: Fabric) |
| Column family data model | Multiple sets of columns | Flat values, wide columns no problem (related: MariaDB Dynamic Columns) |
| Document data model | No column set restrictions. | Values can be nested (related: N1NF/NF2), wide and sparse columns no problem. |
Key-value systems restrict users to atomic key based access. Early systems offered no guarantees when a query spawned multiple values. Take a second and compare with Fabric. How weak is Fabrics’ weak spot?
What makes the query limitations in key-value systems a little less restricting from an application developers point of view is the logical entity a value can hold. Particularily a nested value, as in the document model, can hold multiple logical rows from several flat relational tables. Translated in Fabric speech: document = shard + relevant global tables + x. All MySQL has to offer here are some, limited JSON functions. On an aside: this is only one of many ways to argue why MySQL should have strong JSON/BSON support.
| Simplified applications view on logical data model (see text) | ||
|---|---|---|
| Fabric | Document | |
| Client protocol | Binary (MySQL Client Server), Memcache (to some degree) | Binary (vendor specific), Memcache (sometimes), HTTP (sometimes) |
| (Read) Question | SELECT * FROM tn, gn |
fetch(<key>) |
| (Write) Query | UPDATE tn SET ... WHERE t.shard_key = <key>,UPDATE gn SET ...(requires use of distributed transaction to be atomic) |
update(<key>, <doc>)(single atomic operation) |
| Logical entity | tn+ global table gn
| tn+ global table gn+ any other table un respectively column |
If you are not willing to give up a millimeter on ACID and other RDBMS strengths, stop reading. This is simply not for you. Listing RDBMS strengths for comparison is out of scope for this (already too long) blog post.
Second generation NoSQL NewSQL: co-location
There is a good number of NoSQL solution users today. In 2012 some market researchers predicted upto 25% market loss for MySQL within five years. I doubt those reasearchers included the second generation of NoSQL stores from around 2010 in their results but rather based their prediction on the then popular open source siblings of the 2007 systems. Thus, the 25% is about the simplistic key value model.
The second generation of NoSQL stores continues to aim keeping accesses local to a single node. I am speaking of node here, as partial replication continues to be a must. Second generation systems include but are not limited to ElasTras, H-Store, Megastore, Spanner and – yes – Cloud SQL Server (Microsoft SQL Azure backend). In general, I believe there is some swing back to stricter schemas and declarative SQL-like query languages, however, let’s look at data models only. Let’s consider only data models that are statically defined but none that adapt dynamically to the actual access pattern. To me, a dynamical data model seems out of reach with regards to Fabric.
- hierarchical: tree schema
- hierarchical: entity groups
- [keyed] table group
There are three kinds of (logical) tables in a tree schema: primary tables, secondary tables and global tables. The primary key of the primary table acts as a partitioning key. Secondary tables reference the primary tables using foreign keys. Global tables are additional read-mostly tables available on all nodes.
| Hierarchical: tree schema data model | ||
|---|---|---|
| Primary table p(kp) |
||
| | | | | |
| Secondary table s1(kp, ks1) |
Secondary table s2(kp, ks2) |
|
| Global table g1(kg1) |
… | |
A partition on a node stores all matching records of the primary (sharded) table and the corresponding records in all secondary tables that reference the primary through a foreign key constraint. The records of the tables that are frequently joined are stored together on one node. Plus, additional global tables. It may be possible to use Fabric in a similar way, however, it would be very uncomfortable, possibly complex, manual operation. What’s hot about this approach is that need for distributed transactions for write queries is likely reduced. Its likely that updates spawn primary and secondary tables on one node only.
| Hierarchical: entity group data model | ||
|---|---|---|
| Root table p(keg) |
||
| | | | | |
| Child table c1(keg, kc1) |
Child table c2(keg, kc2) |
|
The basic idea with entity groups is similar. There are root tables/entities and child tables that reference the root tables by foreign keys. Records that reference each other belong together and shall form an entity group. There’s no counterpart to global tables in this model. Again, there is no way to formulate the “those tables belong together” with Fabric.
The table groups data model allows users to define sets of tables that shall be co-located on a node. In their simplest form those sets may consist of arbitrary tables. The tables of a table group may or may relate to each others through foreign keys.
| Keyed table group data model | ||
|---|---|---|
| Row group | ||
| Table t1(kt1, partition_keyc) |
Table t1(kt1, partition_keyc) |
|
Partitioning is applied to keyed tables groups. All tables in a keyed table group have a column that acts as a partitioning key. The partitioning key does not have to be the primary key unlike as in the two models above. All rows in a keyed table group that have the same partition key form a row group. Partitions contain sets of row groups.
The keyed table group model allows a bit more flexibility as neither foreign keys not primary keys have to be taken into account when grouping tables and creating partitions.
Pfft rambling… what’s the moral?
Having written all this, what’s the moral? Well, if you didn’t know before you should know now why partital replication is the key to massive scaleout. Adding partial replication to MySQL means opening Pandora’s box. Accesses spawning multiple nodes become extremly expensive. Fabric has no answer yet how this is to be adressed. One proposal is to move parts of the task towards the drivers. I’m working for the Connectors team and my take is “ouch, really!?”. There are alternatives: adding full replication servers to the farm is one.
As ever, when you hit a problem its good to look around and ask how competition solves it. NoSQL and NewSQL systems know about the issues of distributed transactions. To some degree they work around them and try to reduce the cases when distributed transactions are required. If anyhow possible, queries shall run on individual nodes only. The document model is one prime example. MySQL could bend itself towards the model with relatively low investments.
Second generation NoSQL stores suggest hierarchical models. Again, Fabric could learn a lesson or two – long term. Again, its about avoiding accesses that spawn multiple nodes.
Speaking of distributed transactions: this would make a great topic for an endless follow-up posting titled “Fabric transactions and data model…”.
Happy hacking!

In all fairness…
When I say anything that sounds like “MySQL designed”, I refer to the guys that made MySQL Fabric happen. But, there are countless customers that introduced sharding to the MySQL world long before. It is hard to find adequate wording – the end result is what counts! Replicated databases have been an active area of research since the 1980’s. What’s rather new are the data models that NoSQL systems use to attack the challenges of distributed transactions. What’s also rather new are the stunning WAN/VPN and routing options really big players like Google have.
Pingback: MySQL Fabric with MariaDB Galera Cluster ? « Serge Frezefond 's blog
Pingback: PECL/mysqlnd_ms: Distributed Transaction/XA support coming, e.g. for MySQL Fabric? | Ulf WendelUlf Wendel