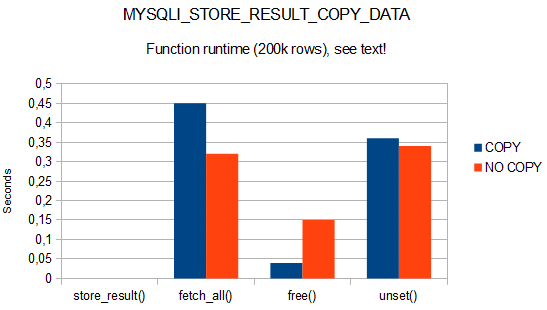
The development version of PECL/mysqlnd_ms now has an very early version of distributed (2PC/XA) transaction support tailored for use with clusters of MySQL servers. XA transactions can span multiple servers in a cluster to ensure transaction guarantees among them. In real life, there is always, at some point, a sequence of work on your data for which atomicity, consistency, isolation, and durability must be given. The early generation of NoSQL sharding solutions has a weak spot here. How do you, as a developer, ensure a logical operation affecting two shards is either applied to both or none? Either you don’t at all, or you hack and pray, or you start reading lecture books on transactions, or you grow your documents to avoid cross-shard operations. MySQL Fabric, our own sharding solution has a gap here too. However, let three new API calls do the troublesome part for you: mysqlnd_ms_xa_begin(), mysqlnd_ms_xa_commit() and mysqlnd_ms_xa_rollback().
| Any sharding cluster: consistent work across shards? | ||||
|---|---|---|---|---|
| Any task that involving more than one shard, for example: copy customer information into order and update order counter stored with customer in one step. Or: update the email of a user in all places – forum users, orders, customers. | ||||
| Shard 1 – Primary | Shard 2 – Primary | |||
| Customers: US residents only | Customers: rest of the world | |||
| Forum users: all | Orders: all | |||
| | | | | | | | | |
| Copy | Copy | Copy | Copy | |
Massive news but where are we on distributed transactions?
The current XA support of the PHP Replication and Load Balacing plugin for mysqlnd is hardly any good – yet! Still, we sort of have a tradition of explaining pain point and feature gaps early. MySQL 5.6/5.7 is on the track learning NoSQL lessons (protocol and query language flexibility, nested data, replication experience), MySQL Fabric is now GA and brings us Sharding and automated High Availability outside MySQL Cluster. Fabric abstracts managing shards, shuffling data around during resharding and telling a client where to find data. Also, the core server improves and some massive pain points from when we started (properly detecting transaction boundaries, reliably finding up-to date replicas) are being addressed.
But: distributed transactions… Lets keep the focus narrow and talk XA only, let’s forget about cross shard joins here. Even if the PHP MySQL APIs had proper XA support (and, of course, it will be so in no more than two hours ;-)), we would hit MySQL limitations. Hence, time to stark the barking.
How it shall look in code… one day
That warning given, let’s talk code. For the “copy customer information into order and update order counter stored with customer in one step” task from the introduction, your code looks like this, if you want transaction guarantees:
/* Connect to cluster: mysqli, PDO_MySQL, ... whatever */
$link = mysqli_connect('my_sharding_cluster', ...);
/* Begin distributed transaction */
mysqlnd_ms_xa_begin($link, $xa_id);
/* Do something on your shards */
mysqlnd_ms_fabric_select_shard($link, "shop.customers", "us_123");
$link->query("SELECT * FROM customer
WHERE key = 'us_123'");
...
$link->query("UPDATE customer SET
order_counter = order_counter + 1
WHERE key = 'us_123'");
mysqlnd_ms_fabric_select_global($link, "shop.orders");
$link->query("INSERT INTO order(...) VALUES (...)");
/* End distributed transaction */
mysqlnd_ms_xa_commit($link, $xa_id);
Remove mysqlnd_ms_xa_begin(), mysqlnd_ms_xa_commit() and you go without distributed transactions. Your choice! Should there be a series of failures at the right time, you get logically inconsistent data without the distributed transaction. With MySQL, invidiual actions will still be consistent as we default to InnoDB these days. InnoDB is nowadays faster than the non-transactional MyISAM from the anchient days of MySQL, and very much so under load.
A word on XA/2PC to illustrate the convenience PECL/mysqlnd_ms brings
The XA specification has 94 pages. The (My)SQL world folds this into six XA related SQL commands. XA follows the two-phase commit protocol. The protocol operates in two rounds and has two distinct players. The players are a coordinator and the participants. In the first phase the coordinator asks all participants whether they are ready to commit some previous work carried out on them.
| Two-phase commit (2PC) in XA: first phase | |||
|---|---|---|---|
| Coordinator | Participant | Participant | Participant |
| –> Vote request | |||
| –> Vote request | |||
| –> Vote request | |||
| <– Pre commit | |||
| <– Pre commit | |||
| <– Pre commit | |||
A participant that replies to the coordinators vote request with a pre commit makes the firm promise that the work done will not be lost even the case of a temporary failure of itself, e.g. when it crashes. But, the pre committed work does not yet become visible to others. Should all participants reply positively to a vote request, the coordinator sends a global commit, which makes the work visible to everybody.
| Two-phase commit (2PC) in XA: second phase | |||
|---|---|---|---|
| Coordinator | Participant | Participant | Participant |
| –> Global commit | |||
| –> Global commit | |||
| –> Global commit | |||
Failures of participants are no problem for the protocol. The coordinator can use timeouts to detect unresponsive participants and either retry after the participant is recovered or send a global rollback to the rest. But should the coordinator crash in the course of informing participants of a global rollback or global commit decision, the protocol becomes a blocking one. The participants wait for instructions.
| Two-phase commit (2PC) in XA: blocking protocol | |||
|---|---|---|---|
| Coordinator | Participant | Participant | Participant |
| –> Global commit | |||
| Crash | |||
| Comitted | Uncomitted: waiting for global commit or rollback | ||
If you call mysqlnd_ms_xa_begin(), PECL/mysqlnd_ms acts as a coordinator. It must handle all the state transitions of the participants, the possible failures of participants and its own failure as a coordinator.
Should you have become curious about 2PC or the challenges of distributed transactions… MySQL Cluster is using two-phase commit internally (2PC), see also the presentation DIY: A distributed database cluster, or: MySQL Cluster or the really in-depth presentation Data massage: How databases have been scaled from one to one million nodes, which takes you from early distributed NoSQL to the very latest developments.
What PECL/mysqlnd_ms does for you, what it hide, where its limited
As said, there are six SQL commands related to XA/2PC:
- Phase 1 related
XA BEGIN– mark the beginning of a unit of work on a participant, telling the participant what to vote aboutXA END– mark the end of the unit of work on a participantXA PREPARE– the pre commit
- Phase 2 related
XA COMMIT– global commitXA ROLLBACK– global rollbackXA RECOVER– error handling: list pre commits
PECL/mysqlnd_ms further compresses this to three API calls. The calls hide issuing the SQL commands on the participants and all the steps a coordinator has to perform. Some features are lost on the way, but convenience is won.
The loss of features is not critical: as a general rule we strive to provide you with a way to overrule any automatic actions, go down to the lower layers and handle anything on your own. The features you loose are choice when participant failures happen and support for other XA participants but MySQL servers. Upon any participant error the automatic action is rollback. Future versions may lift this limitation, I am blogging about pre-alpha development version. At this point, I also have not bothered about any other XA participants but MySQL servers. The XA specification describes distributed transactions for any system implementing a certain API. That could be a database server, a web service or a moon rocket. Other RDBMS also feature SQL commands for XA so that you could have Microsoft SQL Server, IBM’s DB2, Oracle, Postgres and MySQL jointly working on a distributed transactions. If you need that, use the SQL commands directly.
I have had MySQL Fabric in mind, the sharding scenario. Fabric manages farms or clusters of MySQL servers, nothing else. And, MySQL should not loose one of its strength when combined with Fabric: transactions, should you need them.
PECL/mysqlnd_ms as a transaction coordinator
Should you not fear the risk of blocked servers when the coordinator crashes, you can use the new functions straight away.
On mysqlnd_ms_xa_begin(), PECL/mysqlnd_ms will first try to find out whether you are in the middle of a local transaction. Local transactions and global transactions (XA) are mutually exclusive. To detect local transaction boundaries, PECL/mysqlnd_ms monitors all API calls related to them, e.g. mysqli_begin_transaction(), mysqli_autocommit(). It does not monitor SQL commands, such BEGIN TRANSACTION, though. Details are described in the manual. Good news is: mid term the MySQL server will announce transaction boundaries and we can make things bullet proof. Should you not be in the middle of a transaction, it remembers the so-called gtrid (global transaction identified) given in the second parameter: bool mysqlnd_ms_xa_begin(mixed connection, int gtrid). At the time of writing, gtrid is massively limited – I haven’t finished my SQL related C code. That’s for sure a temporary limitation.
Then, as you continue PECL/mysqlnd_ms transparently injects XA BEGIN gtrid on every shard/node that you run a query on. When doing so it also calculates a bqual (branch qualifier) but does not use it yet – for the same reason as above: lazy me, early blogging…
Built-in garbage collection to cover coordinator crashes
I assume most users talking transactions want to see a coordinator crash covered too. This is done by optionally recording all state changing actions in a persistent store that survives a crash. Should the coordinator – your PHP process/script – crash, another process/script can do a garbage collection run to get the participants into a defined state: rollback, clean up.
Garbage collection is built-in. It is done the traditional way: wait for the next PHP process/script to begin its work and run the garbage collection based on a probability value. Very much as PHP sessions or PECL/mysqlnd_qc (query cache plugin) does it. An additional timeout can be configured to decide whether a recorded global transaction is and its coordinator are still active or they should be considered crashed. Had I invested more brain-power already, maybe, the timeout would not be need. Key is: its automatic.
Note that for the garbage collection to work, one needs to record information how to connect to the participants. Recording of user name and password has been made optional and the special meaning of localhost has been thought of. Should the GC be run on a different host but the one who wrote a record with host=localhost, we need to know to which IP localhost refers. Some things are covered and tested – but, this is pre-alpha…
The plugin supports using any data store as a backing store, but only one storage backend is implemented: MySQL. MySQL is transactional, survives crashes and after all we are talking about managing MySQL farms here.
mysqlnd_ms_xa_commit(), mysqlnd_ms_xa_rollback() – note the limitation
Upon mysqlnd_ms_xa_commit(), the plugin becomes chatty. It tells all participants that the work is done (XA END) and gathers pre commit replies (XA PREPARE) to decide on global commit or global rollback. Should all participants give a positive reply, it does send a global commit (XA COMMIT) as requested and mysqlnd_ms_xa_commit() indicates success.
The emergency break is pulled in case of any error with the participants: rollback as much as we can, leave any possible rest to the garbage collection. There is currently no way for the user to react to low-level errors and, for example, do a reconnect to a participant. To handle such cases, the user would need to start handling the connections to participants itself. Any API for doing this would be more complex than just doing everything yourself using SQL and plain vanilla connect()/query() calls! (These lines are being written in early June 2014 – check the manual for updates should you read this later. Some tweaks are likely to happen.)
The function mysqlnd_ms_rollback() also ends the XA transaction on the participants but always sends out a global rollback.
The sad truth: not yet with Fabric, plugin refactoring needed…
Before I can close and move a black jack to the overloaded server folks, well, yeah: it doesn’t work together with Fabric yet. Our fault.
The reason is an implementation detail of PECL/mysqlnd_ms, which is not visible to you. The plugin does not have any dedicated connection management module. We keep a list of all servers of a cluster. When we choose a server for you, say the read-write splitter tells us to use a master, we open a connection and associate it with that server list. When you use Fabric and call mysqlnd_ms_fabric_select_shard()/mysqlnd_ms_fabric_select_global(), as in the example from the beginning, the whole list is replaced. With it, the connections are gone. If there was a participant connection in the list… *ouch*. This is also the reason why I think the state alignment feature is broken when using Fabric.
Fixing this, using a simple option, takes days. However, Andrey, Johannes and I need to find a time to discuss our options. Documenting XA, which I have not done yet, also takes days.
The sad truth: our server has limitations too…
Any server change take way more time for various reasons. The server is more complex, server code plays in a different league, there is little chance of saying we just did it that way, server developers are a rare species and the server has a different release cycle. The server manual reads:
If an XA transaction has reached the PREPARED state and the MySQL server is killed (for example, with kill -9 on Unix) or shuts down abnormally, the transaction can be continued after the server restarts. However, if the client reconnects and commits the transaction, the transaction will be absent from the binary log even though it has been committed. This means the data and the binary log have gone out of synchrony. An implication is that XA cannot be used safely together with replication.
In other words: if you don’t mess around, if you make the emergency break – rollback – approach, as PECL/mysqlnd_ms does, over any attempt to recover, there is a chance it works depite not being bullet proof. I can only hope any server plugin toying with XA keeps an eye on this. The manual then goes on:
It is possible that the server will roll back a pending XA transaction, even one that has reached the PREPARED state. This happens if a client connection terminates and the server continues to run, or if clients are connected and the server shuts down gracefully. (In the latter case, the server marks each connection to be terminated, and then rolls back the PREPARED XA transaction associated with it.) It should be possible to commit or roll back a PREPARED XA transaction, but this cannot be done without changes to the binary logging mechanism.
Again, make the emergency break policy your default, and it may become acceptable. At least for coordinators and implementations tailored for MySQL Fabric. If that’s all the restrictions, and no major bug is lurking around then its time for: how to use distributed transactions with MySQL Fabric sharding ;-).
For proper XA support, as it may be needed by JDBC, these restrictions could be a deal breaker.
Happy PHP hacking!

Background: The PHP replication and load balancing plugin
Happy birthday! Three years ago we pimped all the PHP MySQL APIs to make using any sort of MySQL cluster easier. We began developing a plugin which does all the annoying jobs that clusters may burden developers with: transaction aware read/write splitting if needed, load balancing with the option to assign weight to a replica, connection state alignment when switching servers, automatic client failover, user defined filters/pipes for replica selection, an abstraction for requesting eventual consistency, session consistency (defined as read-your-writes) and strong consistency with a single API call. That is 90% of the infrastructure one needs to get all out of MySQL Fabric. But, MySQL Fabric support is still in the works.
All these things are done on the client side to scale by client. Unlike with basic proxy solutions there is no single point of failure as a single clients failure does not affect the rest.
Yet, if used for nothing but read-write splitting, the ease of use is not compromised. It boils down to installing the plugin and replacing the host name in your APIs connect call mysqli_connect("my_mysql_server", ...)new PDO("mysql:section_from_ms_config", ...). And, as you dig deeper into massive database clustering, you will soon realize how powerful it is to have clients supporting a specific cluster design, for which you just don’t want an all-automatic solution.