I am telling no secret saying MySQL 5.6 GA can be expected to be released soon, very soon. Time to test one of the improvements: MySQL 5.6 speaks SQL and Memcache protocol. In your PHP MySQL apps, try using the Memcache protocol to query MySQL. A key-value SELECT ... FROM ... WHERE pk = <key> can become 1.5x-2x faster, an INSERT INTO table(pk, ...) VALUES (<key> ...) can become 4.5x-9x faster, says the InnoDB team! Read on: background, benchmark, usage, PECL/mysqlnd_memcache, PHP Summit…
Background
Since at least 2009, power users have tried to access MySQL bypassing the SQL layer. SQL is a very rich and powerful query language. But parsing and optimizing SQL takes time. So does a wire protocol that supports all SQL features. A less featured query language and protocol can significantly improve performance. See Key Value stores such as Memcache or Redis: simple queries, simple but fast protocol.
|
Application
|
| MySQL SQL Client |
Memcache Client |
| | |
| |
- rich SQL queries
- strong persistence, safe data store
- no stale data
|
- simple and fast key lookup
- weak persistence, data loss in case of crash
- memcached: often stale data copies from DBMS
|
| | |
| |
| MySQL Server |
Memcached |
Thus, for simple MySQL queries there should be a simple and fast protocol. But which? Many MySQL web deployments use Memcache, I would not be surprised to learn that its the case for 30% of the MySQL web users. The MySQL manual has a chapter dedicated to using Memcached with MySQL. Given the popularity, the choice of a fast protocol for simple key value style queries was easy: MySQL had to learn Memcache protocol.
| MySQL SQL Client |
Memcache Client |
| | |
| |
- rich SQL queries and/or simple and fast key lookup
- persistence: configurable from strong to weak
- no caching, no data copy to sychronize
|
| | |
| MySQL 5.6 with InnoDB Memcache Plugin |
| InnoDB table |
In an ideal world one can run an existing Memcached application against MySQL 5.6 without any code modifications. Future user experience will tell whether the MySQL 5.6 InnoDB Memcache plugin is good enough to replace Memcached installations. There are reasons for considering MySQL as a Memcached replacement (related: Couchbase 2.0) . However, it is the enormous popularity and developer familarity (clients, APIs, usage, …) with Memcached that counts. From an application developer perspective there is little new to learn: change server IP from Memcached to MySQL, done. No more hassles with cold or stale caches…
Benchmarks… never trust them
Really, can MySQL 5.6 replace a Memcached installation? I do not know. As a poP (plain old PHP developer), I focussed on the question whether replacing key value style SQL queries with Memcache access to MySQL could improve PHP application performance. This may be the first step in an evaluation of the new feature.
Of course, I could not resist to run a benchmark MySQL vs. Memcached. As always, never trust benchmarks, run your own tests! All tests have been run on a plain i3-2120T CPU (2 cores, 4 cores counting hyper-threading), 8GB RAM, OpenSuSE 12.1 desktop. Disk configuration is as worse as it can get: soft RAID-1. Due to the poor disk setup I tried to avoid disk access whenever possible, and keep tests running entirely in main memory. Albeit iostat -x has not hinted significant bottlenecks I will not say more on write performance than this. Writes using memcache protocol have been 2x faster than writes using SQL (single INSERT) at the average of some 20 test runs.
Rest of the stack: MySQL 5.6.9-rc (not GA!), memcached 1.4.15, libmemcached 1.0.15, PHP 5.4.11 all compiled using their default settings. Test runs are short, sample variation had to be considered, load generator and server are running on the same machine. This setup is far, far from an ideal one but still something a poP may use.
[mysqld]
innodb_buffer_pool_size = 3072M
daemon_memcached_w_batch_size=1000
daemon_memcached_r_batch_size=1
innodb_flush_log_at_trx_commit=2
innodb_doublewrite=0
Please note, the daemon_memcached_w_batch_size setting is not relevant for the following read performance result. The chart shows the reads per second observed with bin/memslap --servers=127.0.0.1 --concurrency=4 --execute-number=20 --test=get --binary --debug --flush –initial-load=100000. memslap does not report reads per second but you can compute them with the formula: reported_runtime * 10000 / concurrency. Key lenght is 100 bytes, value lenght is 400 bytes, set size is 10,000 rows – memslap defaults…
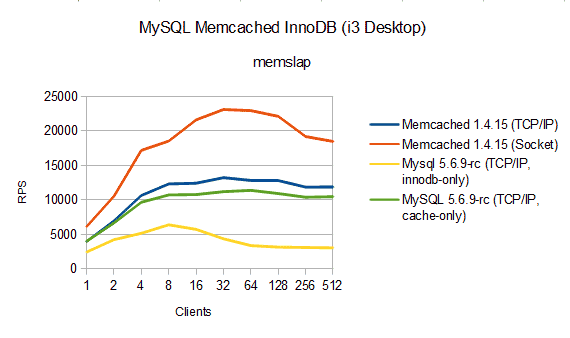
MySQL to replace Memcached?
Memcached performed best if using socket connections. Setting daemon_memcached_option="-s/tmp/mmemcached" made the MySQL 5.6.9-rc1 (non GA) release bind to the socket set but no client was able to perform any queries. Thus, for the question whether MySQL can replace Memcached, we have to look at TCP/IP connection figures.
| MySQL 5.6 |
Memcached running as a MySQL plugin
(as part of the MySQL process) |
| Memcached |
– |
cache_policy=cache_only |
– |
main memory storage |
| | |
|
cache_policy=innodb_only |
| | |
| InnoDB |
The chart shows two TCP/IP figures for MySQL. One shows the results for the MySQL InnoDB Memcached cache policy cache_only, the other one shows results for cache_policy=innodb_only. The MySQL InnoDB Memcached plugin is basically a Memcached running as part of the MySQL process. Memcached supports custom storage backends. The cache_policy sets whether InnoDB or main memory shall be used. In the latter case, the plugin is no different from a standalone Memcached.
Armed with this knowledge you can start comparing MySQL InnoDB Memcached plugin with standalone Memcached. To compare apples and apples you have to compare cache_policy=cache_only with standalone Memcached. Result: little difference. If you compare cache_policy=innodb_only with standalone Memcached you compare apples and oranges! Result for my particular setup: InnoDB turned out slower than Memcached. But recall that you compare apples and oranges: different system architecture, different persistence, possibly no more caching layer…
SQL SELECT versus Memcache get
Sometimes, comparing apples and oranges is perfectly valid. For example, when asking whether to refactor a key value style SQL access (SELECT ... FROM table WHERE pk = <key>) into a Memcached access to MySQL. These kinds of queries are quite typical for applications that use frameworks.
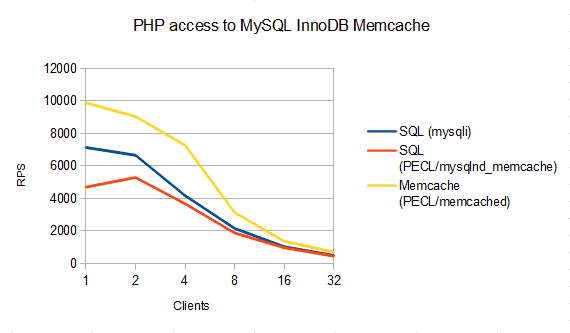
My own benchmark and the InnoDB team benchmark show similar results: try replacing simple SELECT with Memcached accesses, it can give 1,5x … 2x faster queries. The PHP script used is given at the end of the blog post. It is using defaults similar to memslap defaults: key length 100 bytes, value length 400 bytes, 10,000 rows. To minimize impact of the slow disk system on the test computer, the script sleeps for 30 seconds after populating the test table. The SQL access is done using mysqli (w. mysqlnd).
[...]
$res = $mysqli->query($sql = "SELECT c2 FROM demo_test WHERE c1='" . $pairs[$idx][0] . "'");
if (!$res) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
break;
}
$row = $res->fetch_row();
$res->free();
assert($pairs[$idx][1] == $row[0]);
[...]
The equivalent Memcached access is done using PECL/Memcached.
[...]
if (false == ($value = $memc->get($pairs[$idx][0]))) {
printf("[%d] Memc error\n", $memc->getResultCode());
break;
}
assert($pairs[$idx][1] == $value);
[...]
Please note, the benchmark does not take connect times into account. If you replace only few SQL SELECT queries with a Memcache access to MySQL, the connect overhead for the additional Memcache connection to MySQL may outweight performance gains. As always: run your own tests.
PECL/mysqlnd_memcached
Last year Johannes has published PECL/mysqlnd_memcached. PECL/mysqlnd_memcached monitors all queries run by mysqlnd using any PHP MySQL API compiled to use the mysqlnd library. If a query matches a regular expression for a key value style SELECT, then the plugin transparently performs a Memcached access instead of a SQL access to MySQL. Back then, we found cases in which this gave a slight performance increase of some 20…30%. With my recent benchmark I got some performance loss using PECL/mysqlnd_memcache compared to a plain SQL access with mysqli. As always: run your own tests. However, this hints that an automatic and transparent runtime replacement may not be fast enough.
Finding SQL SELECT key value style queries
Refactoring existing applications may be a better solution. There are two mysqlnd plugins that can help to identify queries that qualify for refactoring: PECL/mysqlnd_uh (PHP 5.3 only), PECL/mysqlnd_qc (PHP 5.3 and above). PECL/mysqlnd_uh enables you to rebuild PECL/mysqlnd_memcached using PHP instead of C. The blog post
Uh, uh… extending mysqlnd: monitoring and statement redirection gets you started. A PHP 5.4+ compatible alternatives are the mysqlnd_qc_get_normalized_query_trace_log() and mysqlnd_qc_get_query_trace_log() functions provided by PECL/mysqlnd_qc. The functions help you to find the origin of SQL SELECT key value style queries by providing traces of all queries executed. Please note, it is not necessary to turn on the actual caching functionality of the client-side cache plugin PECL/mysqlnd_qc to access the query traces.
Apples, oranges and other peoples benchmarks…
Albeit artificial benchmarks hint a significant performance benefit, real life gains have to be evaluated on a case by case basis. For example, you may decide not to commit after each read/get and run InnoDB in read-only mode on a slave server. Thus, you set daemon_memcached_r_batch_size=64 and/or innodb_read_only in your MySQL configuration. Setting either one can double reads per second, peaking around 21,000 reads/s from MySQL 5.6 on an Intel-i3 based desktop. Still slower than Memcached but the features are different…
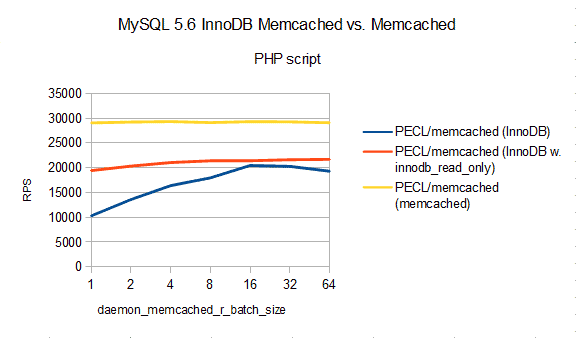
Really, there is something here…
A look at the performance shows that there is something here. Next, one will have to take a look at the feature difference and compare with other approaches in MySQL land. That’s the story to tell in my talk at the PHP Summit.
Finally, stability: good enough to start testing. MySQL 5.6.9-rc was reasonable stable to run benchmarks against it but not perfectly stable. PECL/mysqlnd_memcached beta needs to be brushed over to reflect the latest changes. We will do that once MySQL 5.6 GA has been published.
Happy hacking!
@Ulf_Wendel 
PHP benchmark script used
<?php
define("MYSQL_HOST", "127.0.0.1");
define("MYSQL_USER", "root");
define("MYSQL_PWD", "");
define("MYSQL_DB", "test");
define("MYSQL_PORT", 3307);
define("MYSQL_MEMC_PORT", 11211);
define("NUM_VALUES", 10000);
define("REPEAT_READS", 10);
/* Wait time e.g. for background commit */
define("REST_TIME_AFTER_LOAD", 30);
/* Make sure the schema matches! */
define("KEY_LEN", 10);
define("VALUE_LEN", 100);
/* match MySQL config to be fair... */
define("WRITE_COMMIT_BATCH_SIZE", 1000);
/* number of parallel fetch worker (processes) */
define("FETCH_WORKER", 2);
function store_fetch_results_in_mysql($run_id, $pid, $results, $num_values = NUM_VALUES, $repeat = REPEAT_READS) {
$mysqli = new mysqli(MYSQL_HOST, MYSQL_USER, MYSQL_PWD, MYSQL_DB, MYSQL_PORT);
if ($mysqli->errno) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
return false;
}
if (!$mysqli->query("CREATE TABLE IF NOT EXISTS php_bench(
run_id INT, pid INT UNSIGNED,
label VARCHAR(60),
runtime DECIMAL(10, 6) UNSIGNED, ops INT UNSIGNED)")) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
return false;
}
foreach ($results as $label => $time) {
$sql = sprintf("INSERT INTO php_bench(run_id, pid, label, runtime, ops)
VALUES (%d, %d, '%s', %10.6f, %d)",
$run_id,
$pid,
$mysqli->real_escape_string($label),
$time,
($time > 0) ? ($num_values * $repeat / $time) : 0);
if (!$mysqli->query($sql)) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
return false;
}
}
return true;
}
function generate_pairs($num = NUM_VALUES, $key_len = KEY_LEN, $value_len = VALUE_LEN) {
$pairs = array();
$anum = "0123456789ABCDEFGHIJKLMNOPQRSTWXYZabcdefghijklmnopqrstuvwxyz";
$anum_len = strlen($anum) - 1;
for ($i = 0; $i < $num; $i++) {
$key = "";
for ($j = 0; $j < $key_len; $j++) {
$key .= substr($anum, mt_rand(0, $anum_len), 1);
}
$value = $key . strrev($key) . $key . strrev($key);
$pairs[] = array($key, $value);
}
return $pairs;
}
function load_pairs_memc($memc, $pairs) {
$inserted = 0;
foreach ($pairs as $k => $pair) {
if (false == $memc->add($pair[0], $pair[1])) {
printf("[%d] Memc error\n", $memc->getResultCode());
break;
}
$inserted++;
}
return $inserted;
}
function load_pairs_sql($mysqli, $pairs) {
$inserted = 0;
$mysqli->autocommit = false;
foreach ($pairs as $k => $pair) {
if (!$mysqli->query(sprintf("INSERT INTO demo_test(c1, c2) VALUES ('%s', '%s')", $pair[0], $pair[1]))) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
break;
}
$inserted++;
if ($inserted % WRITE_COMMIT_BATCH_SIZE == 0) {
$mysqli->commit();
}
}
$mysqli->commit();
$mysqli->autocommit = true;
return $inserted;
}
function timer($label = '') {
static $times = array();
if (!$label)
return $times;
my_timer($label, $times);
return $times;
}
function my_timer($label, &$times) {
if (!$label)
return;
if (!isset($times[$label])) {
$times[$label] = microtime(true);
} else {
$times[$label] = microtime(true) - $times[$label];
}
}
function fetch_sql($mysqli, $pairs, $repeat = REPEAT_READS) {
$fetched = 0;
for ($i = 0; $i < $repeat; $i++) {
$fetched += _fetch_sql($mysqli, $pairs);
}
return $fetched;
}
function _fetch_sql($mysqli, $pairs) {
$fetched = 0;
$num = count($pairs);
while (count($pairs)) {
do {
$idx = mt_rand(0, $num);
} while (!isset($pairs[$idx]));
$res = $mysqli->query($sql = "SELECT c2 FROM demo_test WHERE c1='" . $pairs[$idx][0] . "'");
if (!$res) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
break;
}
$row = $res->fetch_row();
$res->free();
assert($pairs[$idx][1] == $row[0]);
$fetched++;
unset($pairs[$idx]);
}
return $fetched;
}
function fetch_memc($memc, $pairs, $repeat = REPEAT_READS) {
$fetched = 0;
for ($i = 0; $i < $repeat; $i++) {
$fetched += _fetch_memc($memc, $pairs);
}
return $fetched;
}
function _fetch_memc($memc, $pairs, $repeat = 1) {
$fetched = 0;
$num = count($pairs);
while (count($pairs)) {
do {
$idx = mt_rand(0, $num);
} while (!isset($pairs[$idx]));
if (false == ($value = $memc->get($pairs[$idx][0]))) {
printf("[%d] Memc error\n", $memc->getResultCode());
break;
}
assert($pairs[$idx][1] == $value);
$fetched++;
unset($pairs[$idx]);
}
return $fetched;
}
function generate_and_load_pairs($num = NUM_VALUES, $key_len = KEY_LEN, $value_len = VALUE_LEN) {
$mysqli = new mysqli(MYSQL_HOST, MYSQL_USER, MYSQL_PWD, MYSQL_DB, MYSQL_PORT);
if ($mysqli->errno) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
return array();
}
$memc = new Memcached();
if (!$memc->addServer(MYSQL_HOST, MYSQL_MEMC_PORT)) {
printf("[%d] Memc connect error\n", $memc->getResultCode());
return array();
}
timer("generate pairs");
printf("\tGenerating pairs...\n");
$pairs = generate_pairs($num, $key_len, $value_len);
timer("generate pairs");
timer("load pairs using SQL");
printf("\tLoading %d pairs using SQL...\n", load_pairs_sql($mysqli, $pairs));
timer("load pairs using SQL");
$mysqli->query("DELETE from demo_test");
/* server think and commit time */
sleep(REST_TIME_AFTER_LOAD);
timer("load pairs using Memcache");
printf("\tLoading %d pairs using Memcache...\n", load_pairs_memc($memc, $pairs));
timer("load pairs using Memcache");
sleep(REST_TIME_AFTER_LOAD);
return $pairs;
}
function fetch_and_bench($pairs, $pid, $indent = 1, $repeat = REPEAT_READS) {
$times = array();
$mysqli = new mysqli(MYSQL_HOST, MYSQL_USER, MYSQL_PWD, MYSQL_DB, MYSQL_PORT);
if ($mysqli->errno) {
printf("[%d] %s\n", $mysqli->errno, $mysqli->error);
return $times;
}
$memc = new Memcached();
if (!$memc->addServer(MYSQL_HOST, MYSQL_MEMC_PORT)) {
printf("[%d] Memc connect error\n", $memc->getResultCode());
return $times;
}
$prefix = str_repeat("\t", $indent);
my_timer("fetch using plain SQL", $times);
printf("%s[pid = %d] Fetched %d pairs using plain SQL...\n", $prefix, $pid, fetch_sql($mysqli, $pairs, $repeat));
my_timer("fetch using plain SQL", $times);
mysqlnd_memcache_set($mysqli, $memc);
my_timer("fetch using Memcache mapped SQL", $times);
printf("%s[pid = %d] Fetched %d pairs using Memcache mapped SQL...\n", $prefix, $pid, fetch_sql($mysqli, $pairs, $repeat));
my_timer("fetch using Memcache mapped SQL", $times);
my_timer("fetch using Memcache", $times);
printf("%s[pid = %d] Fetched %d pairs using Memcache...\n", $prefix, $pid, fetch_memc($memc, $pairs, $repeat));
my_timer("fetch using Memcache", $times);
return $times;;
}
$run_id = mt_rand(0, 1000);
$pairs = generate_and_load_pairs(NUM_VALUES, KEY_LEN, VALUE_LEN);
$load_times = timer();
$pids = array();
for ($fetch_worker = 1; $fetch_worker <= FETCH_WORKER; $fetch_worker++) {
switch ($pid = pcntl_fork()) {
case -1:
printf("Fork failed!\n");
break;
case 0:
printf("\t\tFetch worker %d (pid = %d) begins...\n", $fetch_worker, getmypid());
$times = fetch_and_bench($pairs, getmypid(), 2);
store_fetch_results_in_mysql($run_id, getmypid(), $times, NUM_VALUES, REPEAT_READS);
printf("\t\tWorker %d (pid = %d) has recorded its results...\n", $fetch_worker, getmypid());
exit(0);
break;
default:
printf("\t\tParent has created worker [%d] (pid = %d)\n", $fetch_worker, $pid);
$pids[] = $pid;
pcntl_waitpid($pid, $status, WNOHANG);
break;
}
}
foreach ($pids as $pid) {
pcntl_waitpid($pid, $status);
}
printf("\n\n");
printf("Key settings\n");
printf("\t%60s: %d\n", "Number of values", NUM_VALUES);
printf("\t%60s: %d\n", "Key length", KEY_LEN);
printf("\t%60s: %d\n", "Value length", VALUE_LEN);
printf("\t%60s: %d\n", "SQL write commit batch size", WRITE_COMMIT_BATCH_SIZE);
printf("\t%60s: %d\n", "Parallel clients (fetch)", FETCH_WORKER);
printf("\t%60s: %d\n", "Run ID used to record fetch times in MySQL", $run_id);
printf("\n\n");
printf("Load times\n");
foreach ($load_times as $label => $time) {
printf("\t%60s: %.3fs (%d ops)\n", $label, $time, NUM_VALUES / $time);
}
printf("\n");
printf("Fetch times\n");
$mysqli = new mysqli(MYSQL_HOST, MYSQL_USER, MYSQL_PWD, MYSQL_DB, MYSQL_PORT);
if ($mysqli->errno) {
die(sprintf("[%d] %s\n", $mysqli->errno, $mysqli->error));
}
$res = $mysqli->query("SELECT DISTINCT label FROM php_bench WHERE run_id = " . $run_id);
if (!$res)
die(sprintf("[%d] %s\n", $mysqli->errno, $mysqli->error));
while ($row = $res->fetch_assoc()) {
$sql = sprintf("SELECT AVG(runtime) as _time, AVG(ops) AS _ops FROM php_bench WHERE label = '%s' GROUP BY run_id HAVING run_id = %d",
$mysqli->real_escape_string($row['label']),
$run_id);
if (!($res2 = $mysqli->query($sql)))
die(sprintf("[%d] %s\n", $mysqli->errno, $mysqli->error));
$row2 = $res2->fetch_assoc();
printf("\t%60s: %.3fs (%d ops)\n", $row['label'], $row2['_time'], $row2['_ops']);
}
$mysqli->query("DELETE FROM php_bench");
printf("\n\n");
printf("\t\tTHE END\n");

